Import Data in SpectroChemPy
This tutorial shows how to import data in SpectroChemPy (SCPy) .
First, let’s import spectrochempy as scp in the current namespace, so that all spectrochempy commands will be called as scp.method(<method parameters>) .
[1]:
import spectrochempy as scp

|
SpectroChemPy's API - v.0.7.1 © Copyright 2014-2025 - A.Travert & C.Fernandez @ LCS |
Dialog boxes
Retrieving Files and Directories, in day-to-day work is often made through Dialog Boxes. While we do not recommend this procedure for advanced usage (see below), it is quite easy to do that with SCPy. To do so, we can use the read function which open a dialog, allowing the selection of data file form various origin. By default, the native SCPy type of data is proposed (file suffix: .scp ). The desired type of files to display can be chosen in a dropdown field.
[2]:
X = scp.read()
The dialog box such as shown in this image:
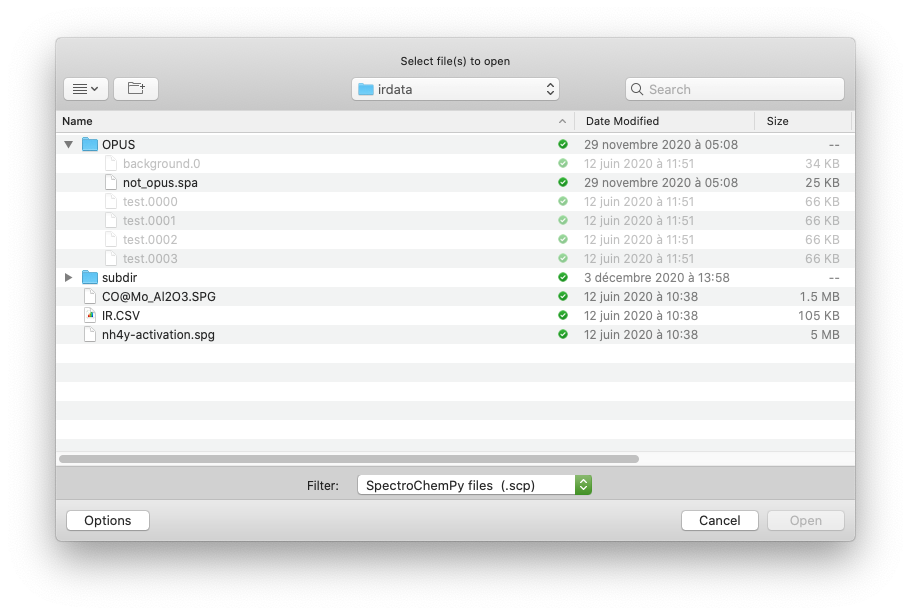
The dialog Box allows selecting the file which data will be loaded in the variable X. Try for instance to run the cell below, and select an omnic spg datafile (select the .spg extension), which you can find in the irdata directory.
Tip
the dialog box does not necessarily pop up in the foreground: check your task bar !
Printing the returned NDDataset object X should read like this, with indication of the dataset shape , i.e., the y and x dimension sizes:
[3]:
print(X)
NDDataset: [float64] a.u. (shape: (y:55, x:5549))
The size of the y and x dimension will depend, of course, of the file that you have selected ! If you did not select any file ( e.g., by pressing ‘cancel’ in th Dialog Box), the result will be None , as nothing has been loaded in X .
Note
By default, the Dialog Box opens in the last directory you have used. However, if a directory path is specified, the dialog should open from this directory.
[4]:
X = scp.read_omnic(
"irdata/subdir"
) # a WARNING is issued when some files are unreadable in the subdir (and thus ignored)
print(X)
[NDDataset: [float64] a.u. (shape: (y:335, x:1868)), NDDataset: [float64] a.u. (shape: (y:4, x:5549))]
See below for more information
At the time of writing this tutorial (SpectroChemPy v.0.1.23), the following commands will behave similarly:
readto open any kind of recognised data files based on the file suffix (e.g., .spg, etc…)read_omnicto open omnic (spa and spg) filesread_opusto open Bruker Opus (.0, …) filesread_labspecto open LABSPEC6 files - this assumes they have been exported as .txt filesread_topspinto open Bruker Topspin NMR filesread_csvto open csv filesread_jcampto open an IR JCAMP-DX datafileread_matlabto open MATLAB (.mat) files including Eingenvector’s Dataset objects
Additionally
read_dirto open readable files in a directory
The list of readers available will hopefully increase in future SCPy releases.
If successful, the output of the above cell should read something like
Out[2] NDDataset: [float64] a.u. (shape: (y:4, x:5549))
Import with explicit directory or file pathnames
While the use of Dialog Box seems at first ‘user-friendly’, you will probably experience that this is often NOT efficient because you will have to select the file each time the notebook (or the script) is run… Hence, the above commands can be used with the indication of the path to a directory, and/or to a filename.
If only a directory is indicated, the dialog box will open in this directory.
Note that on Windows the path separator is a backslash \\ . However, in many contexts, backslash is also used as an escape character in order to represent non-printable characters. To avoid problems, either it has to be escaped itself, a double backslash or one can also use raw string literals to represent Windows paths. These are string literals that have an r prepended to them. In raw string literals the \\ represents a literal backslash: r'C:\users\Brian' :
For instance, on Windows systems, the two following commands are fully equivalent:
X = scp.read_omnic(directory='C:\\users\\Brian')
or
X = scp.read_omnic(directory=r'C:\users\Brian')
and will open the dialog box at the root directory of the C: drive.
You can avoid using the form \\ or the use of raw strings by using conventional slash / . In python, they play the path separator role, as well in Windows than in other UNIX-based system (Linux, OSX, …)
X = scp.read_omnic(directory='C:/users/Brian')
If a filename is passed in argument, like here:
X = scp.read_omnic('wodger.spg', directory='C:/')
then SpectroChemPy will attempt opening a file named wodger.spg supposedly located in C:\\ .
Imagine now that the file of interest is actually located in C:\users\Brian\s\Life . The following commands are all equivalent and will allow opening the file:
using only the full pathname of the file:
X = scp.read_omnic('C:/users/Brian/s/Life/wodger.spg')
or using a combination of directory and file pathnames:
X = scp.read_omnic('wodger.spg', directory='C:/users/Brian/s/Life'
X = scp.read_omnic('Life/wodger.spg', directory='C:/users/Brian/s')
etc…
A good practice: use relative paths
The above directives require explicitly writing the absolute pathnames, which are virtually always computer specific. If, for instance, Brian has a project organised in a folder (s ) with a directory dedicated to input data (Life ) and a notebook for preprocessing (welease.ipynb ) as illustrate below:
C:\users
| +-- Brian
| | +-- s
| | | +-- Life
| | | | +-- wodger.spg
| | | +-- welease.ipynb
Then running this project in John’s Linux computer (e.g. in /home/john/s_copy ) will certainly result in execution errors if absolute paths are used in the notebook:
OSError: Can't find this filename C:\users\Brian\s\life\wodger.spg
In this respect, a good practice consists in using relative pathnames in scripts and notebooks. Fortunately, SpectroChemPy readers use relative paths. If the given path is not absolute, then SpectroChemPy will search in the current directory. Hence, the opening of the spg file from scripts in welease.ipynb can be made by the command:
X = scp.read_omnic('Life/wodger.spg')
or:
X = scp.read_omnic('wodger.spg', directory='Life')
Good practice: use os or pathlib modules
In python, working with pathnames is classically done with dedicated modules such as os or pathlib python modules. With os we mention the following methods that can be particularly useful:
import os
os.getcwd() # returns the absolute path of the current working directory
# preferences.datadir
os.path.expanduser("~") # returns the home directory of the user
os.path.join('path1','path2','path3', ...)
# intelligently concatenates path components
# using the system separator (`/` or `\\` )
Using Pathlib is even simpler:
from pathlib import Path
Path.cwd() # returns the absolute path of the current working directory
Path.home() # returns the home directory of the user
Path('path1') / 'path2' / 'path3' / '...' # intelligently concatenates path
components
The interested readers will find more details on the use of these modules here:
Another default search directory: datadir
Spectrochempy also comes with the definition of a second default directory path where to look at the data: the datadir directory. It is defined in the variable preferences.datadir which is imported at the same time as spectrochempy. By default, datadir points in the ‘$HOME/.spectrochempy/tesdata’ directory.:
[5]:
DATADIR = scp.preferences.datadir
DATADIR
[5]:
PosixPath('/home/runner/.spectrochempy/testdata')
DATADIR is already a pathlib object and so can be used easily
[6]:
X = scp.read_omnic(DATADIR / "wodger.spg")
It can be set to another pathname permanently (i.e., even after computer restart) by a new assignment:
scp.preferences.datadir = 'C:/users/Brian/s/Life'
This will change the default value in the SCPy preference file located in the hidden folder .spectrochempy/ at the root of the user home directory.
Finally, by default, the import functions used in Spectrochempy will search the data files using this order of precedence:
try absolute path
try in current working directory
try in
datadirif none of these works: generate an OSError (file or directory not found)