Note
Go to the end to download the full example code.
PCA example (iris dataset)
In this example, we perform the PCA dimensionality reduction of the classical iris
dataset (Ronald A. Fisher.
“The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7, pp.179-188, 1936).
Load the SpectroChemPy API package
import spectrochempy as scp
Load the Iris dataset
dataset = scp.load_iris()
Fit a PCA model with automatic component selection
Using n_components="mle", the optimal number of components is determined
automatically. Note: "mle" cannot be used when n_observations < n_features.
The number of components found is 3:
3
It explains 99.5% of the variance:
pca.cumulative_explained_variance[-1].value
Fit a PCA model with a variance threshold
We can also specify the amount of explained variance directly:
This time 4 components are found:
4
Inspect the loadings and scores
The 4 components (loadings) are accessible via pca.components:
or equivalently via pca.loadings:
To reduce the data to a lower dimensionality, use transform:
The scores are also available directly via pca.scores:
The explained and cumulative variance can be printed:
Visualize the results
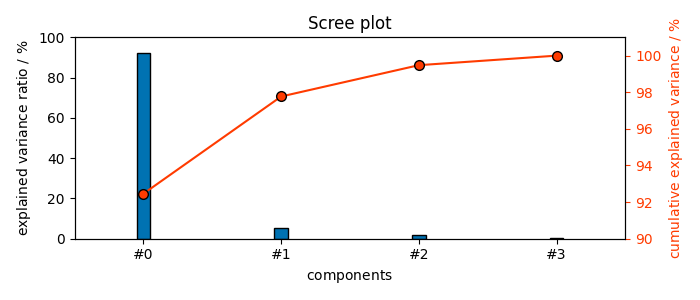
The scree plot shows the explained variance per component:
_ = pca.plot_scree()
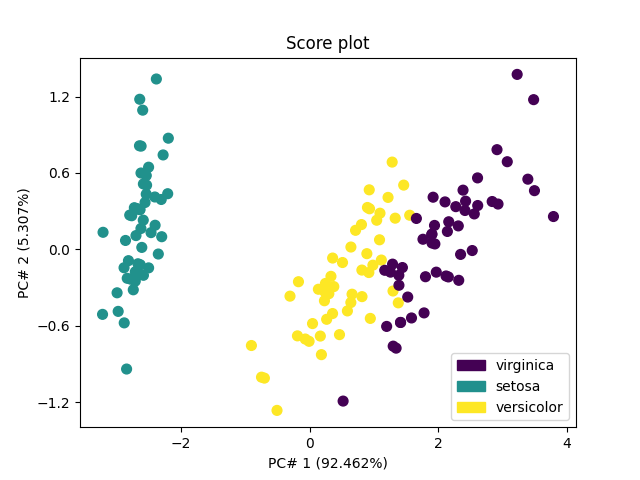
The 2D score plot (first 2 PCs) separates Iris-setosa from the other species:
_ = pca.plot_score(color_mapping="labels")

The 3D score plot (first 3 PCs) shows that a third PC does not further distinguish versicolor from virginica:
ax = pca.plot_score(components=(1, 2, 3), color_mapping="labels")
ax.view_init(10, 75)
This ends the example ! The following line can be uncommented if no plot shows when running the .py script with python
# scp.show()
Total running time of the script: (0 minutes 0.706 seconds)