spectrochempy.read
- read(*paths, **kwargs)[source]
Read data from various file formats.
This is the central user-facing entry point for SpectroChemPy file import. In the current API convention,
read()is the generic dispatcher while namespace readers such asscp.omnic.read(...),scp.opus.read(...),scp.matlab.read(...), or plugin readers provide the explicit format-specific forms. Useread()when automatic format detection is desired and use a namespace reader when the data source is already known.read()generally detects the file format from the filename extension and then delegates to the corresponding public reader implementation. You can bypass detection by passing theprotocolkeyword explicitly.Depending on the input,
read()may return either a singleNDDatasetor a list-likeScpObjectList. The latter occurs when several datasets are discovered and not merged into one result. In that case, helper features such as.names,.select_largest(),.select_by_name(),.filter_by_ndim(), and.filter_by_shape()provide an idiomatic public way to inspect and select the desired dataset without dropping down to ad hoc list-handling code.- Parameters:
*paths (
str,Pathobject objects or valid urls, optional) – The data source(s) can be specified by the name or a list of name for the file(s) to be loaded:e.g., ( filename1, filename2, …, kwargs )
If the list of filenames are enclosed into brackets:
e.g., ( [filename1, filename2, …], kwargs )
The returned datasets are merged to form a single dataset, except if
mergeis set toFalse.**kwargs (keyword parameters, optional) – See Other Parameters.
- Returns:
object (
NDDatasetorScpObjectListofNDDataset) – The returned dataset(s). When several datasets are returned without merging, the result is a list-likeScpObjectListwith convenience helpers such as.names,.select_largest(),.select_by_name(),.filter_by_ndim(), and.filter_by_shape().- Other Parameters:
content (
bytesobject, optional) – Instead of passing a filename for further reading, a bytes content can be directly provided as bytes objects. The most convenient way is to use a dictionary. This feature is particularly useful for a GUI Dash application to handle drag and drop of files into a Browser.csv_delimiter (
str, optional, default:csv_delimiter) – Set the column delimiter in CSV file.description (
str, optional) – A custom description.directory (
Pathobject objects or valid urls, optional) – From where to read the files.download_only (
bool, optional, default:False) – Used only when url are specified. If True, only downloading and saving of the files is performed, with no attempt to read their content.merge (
bool, optional, default:False) – IfTrueand several filenames or adirectoryhave been provided as arguments, then a singleNDDatasetwith merged dataset (stacked along the first dimension) is returned. In the case not all datasets have compatible dimensions or types/origins, then several NDDatasets can be returned for different groups of compatible datasets.origin (str, optional) – If provided it may be used to define the type of experiment: e.g., ‘ir’, ‘raman’,.. or the origin of the data, e.g., ‘omnic’, ‘opus’, … It is often provided by the reader automatically, but can be set manually.
It is used, for instance, when reading a directory with different types of files and merging compatible datasets into separate groups by origin.
It is also used when reading with the CSV protocol. In order to properly interpret CSV file it can be necessary to set the origin of the spectra. Up to now only
'omnic'and'tga'have been implemented.pattern (
str, optional) – A pattern to filter the files to read.Added in version 0.7.2.
protocol (
str, optional) –Protocolused for reading, for example'scp','omnic','opus','matlab','jcamp','csv'or a plugin-provided protocol. If not provided, the correct protocol is inferred whenever possible from the filename extension.read_only (
bool, optional, default:True) – Used only when url are specified. If True, saving of the files is performed in the current directory, or in the directory specified by the directory parameter.recursive (
bool, optional, default:False) – Read also in subfolders.replace_existing (
bool, optional, default:False) – Used only when url are specified. By default, existing files are not replaced so not downloaded.sortbydate (
bool, optional, default:True) – Sort multiple filename by acquisition date.
See also
spectrochempy.read_zipRead Zip archives (containing spectrochempy readable files)
spectrochempy.read_dirRead an entire directory.
spectrochempy.read_opusRead OPUS spectra.
spectrochempy.read_labspecRead Raman LABSPEC spectra (
.txt).spectrochempy.read_omnicRead Omnic spectra (
.spa,.spg,.srs).spectrochempy.read_socRead Surface Optics Corp. files (
.ddr,.hdr, or.sdr).spectrochempy.read_spcRead Galactic files (
.spc).spectrochempy.read_quaderaRead a Pfeiffer Vacuum’s QUADERA mass spectrometer software file.
spectrochempy.read_csvRead CSV files (
.csv).spectrochempy.read_matlabRead Matlab files (
.mat,.dso).spectrochempy.read_wireRead Renishaw Wire files (
.wdf).
Examples
Reading a single OPUS file (providing a windows type filename relative to the default
datadir)>>> scp.read('irdata\\OPUS\\test.0000') NDDataset: [float64] a.u. (shape: (y:1, x:2567))
Reading a single OPUS file (providing a unix/python type filename relative to the default
datadir) Note that here read_opus is called as a classmethod of the NDDataset class>>> scp.read('irdata/OPUS/test.0000') NDDataset: [float64] a.u. (shape: (y:1, x:2567))
Single file specified with pathlib.Path object
>>> from pathlib import Path >>> folder = Path('irdata/OPUS') >>> p = folder / 'test.0000' >>> scp.read(p) NDDataset: [float64] a.u. (shape: (y:1, x:2567))
Multiple files not merged (return a list-like multi-dataset result). Note that a directory is specified
>>> le = scp.read('test.0000', 'test.0001', 'test.0002', directory='irdata/OPUS') >>> len(le) 3 >>> names = le.names >>> len(names) 3 >>> le[0] NDDataset: [float64] a.u. (shape: (y:1, x:2567))
Multiple files merged as the
mergekeyword is set to true>>> scp.read('test.0000', 'test.0001', 'test.0002', directory='irdata/OPUS', merge=True) NDDataset: [float64] a.u. (shape: (y:3, x:2567))
Multiple files to merge : they are passed as a list instead of using the keyword
>>> scp.read(['test.0000', 'test.0001', 'test.0002'], directory='irdata/OPUS') NDDataset: [float64] a.u. (shape: (y:3, x:2567))
Multiple files not merged : they are passed as a list but
mergeis set to false>>> le = scp.read(['test.0000', 'test.0001', 'test.0002'], directory='irdata/OPUS', merge=False) >>> len(le) 3 >>> largest = le.select_largest() >>> largest.shape (1, 2567)
Read without a filename. This has the effect of opening a dialog for file(s) selection
>>> nd = scp.read()
Read in a directory (assume that only OPUS files are present in the directory (else we must use the generic
readfunction instead)>>> le = scp.read(directory='irdata/OPUS') >>> len(le) 2 >>> largest = le.select_largest() >>> largest.ndim 2
Again we can use merge to stack all 4 spectra if they have compatible dimensions.
>>> scp.read(directory='irdata/OPUS', merge=True) [NDDataset: [float64] a.u. (shape: (y:1, x:2567)), NDDataset: [float64] a.u. (shape: (y:4, x:2567))]
Examples using spectrochempy.read
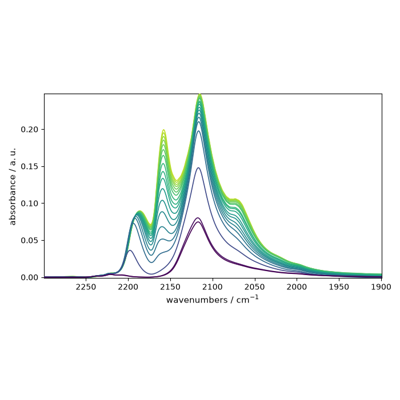
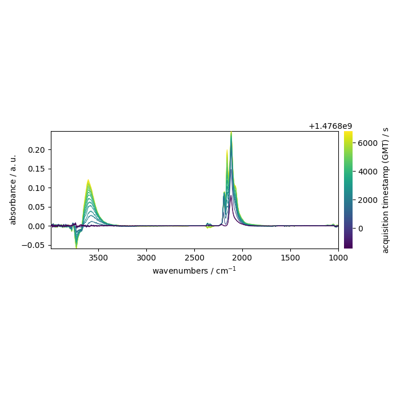
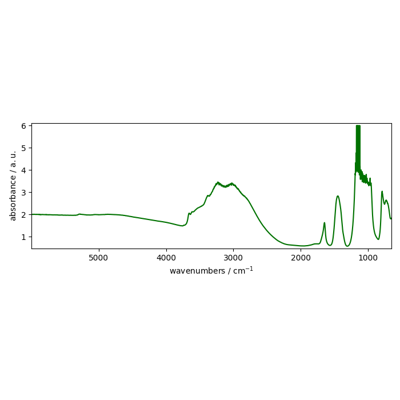
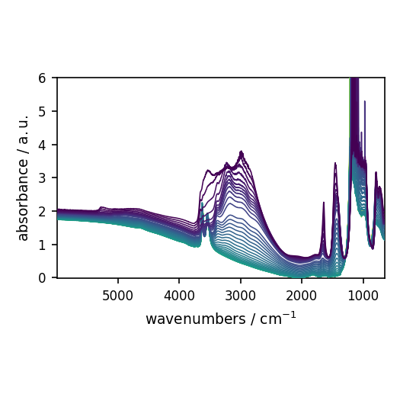
Using plot_multiple to plot several datasets on the same figure
Savitky-Golay and Whittaker-Eilers smoothing of a Raman spectrum
Compare smoothing window sizes on a Raman spectrum