Note
Go to the end to download the full example code.
Preprocessing transformers and scikit-learn compatibility
SpectroChemPy preprocessing operations can be used as stateful transformers that learn statistics from a training set and reuse them on new data. This is essential for machine-learning workflows where train and test sets must be processed with the same scaling parameters.
The transformers also expose get_params() / set_params() so they
work with sklearn.base.clone() when scikit-learn is installed.
Load data
import numpy as np
import spectrochempy as scp
dataset = scp.read_omnic("irdata/nh4y-activation.spg")
region = dataset[:, 4000.0:2000.0]
Train / test split
We keep the first 40 spectra for training and the rest for testing.
Stateful scaling with AutoscaleTransformer
fit_transform() learns the mean and std on train (per wavenumber,
dim='y'), then scales train. transform() later applies the
same parameters to test — no data leakage.
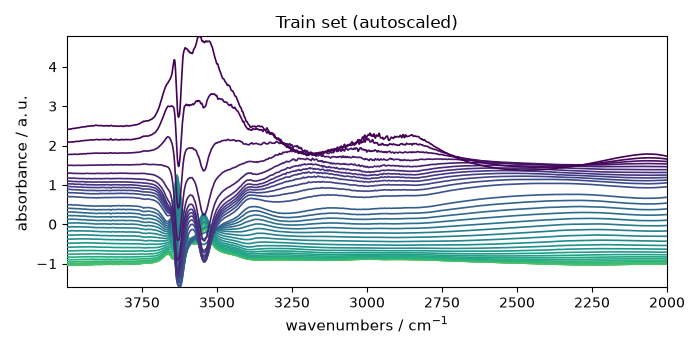
scaler = scp.AutoscaleTransformer(dim="y")
X_train_scaled = scaler.fit_transform(X_train)
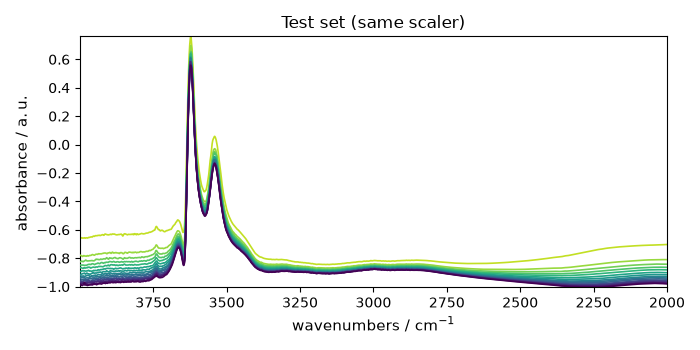
X_test_scaled = scaler.transform(X_test)
_ = X_train_scaled.plot(title="Train set (autoscaled)")
_ = X_test_scaled.plot(title="Test set (same scaler)")
Inspecting learned parameters
The transformer stores the statistics as NumPy arrays.
print("Mean shape:", scaler.mean_.shape)
print("Std shape: ", scaler.std_.shape)
Mean shape: (1, 2075)
Std shape: (1, 2075)
Parameter inspection with get_params / set_params
All transformers follow scikit-learn conventions.
print("Original params:", scaler.get_params())
# Change the target dimension
scaler.set_params(dim="x")
print("After set_params:", scaler.get_params())
Original params: {'dim': 'y'}
After set_params: {'dim': 'x'}
sklearn.base.clone compatibility
When scikit-learn is available, transformers can be cloned exactly like any sklearn estimator.
try:
from sklearn.base import clone
original = scp.AutoscaleTransformer(dim="x")
original.fit(X_train)
cloned = clone(original)
print("Clone has same params:", cloned.get_params() == original.get_params())
print("Clone is not fitted yet:", not cloned._fitted)
except ImportError:
print("scikit-learn not installed — clone example skipped")
Clone has same params: True
Clone is not fitted yet: True
Inverse transform
inverse_transform() restores the original absorbance units. This
is useful when interpreting model predictions (e.g., converting
PCA scores back to original space).
X_train_restored = scaler.set_params(dim="y").inverse_transform(X_train_scaled)
print(
"Restored data matches original?",
np.allclose(X_train_restored.data, X_train.data),
)
Restored data matches original? True
This ends the example. Uncomment the next line to display the figures when running the script directly with Python.
# scp.show()
Total running time of the script: (0 minutes 0.515 seconds)